Beyond 'video as black boxes'
2013 Apr 08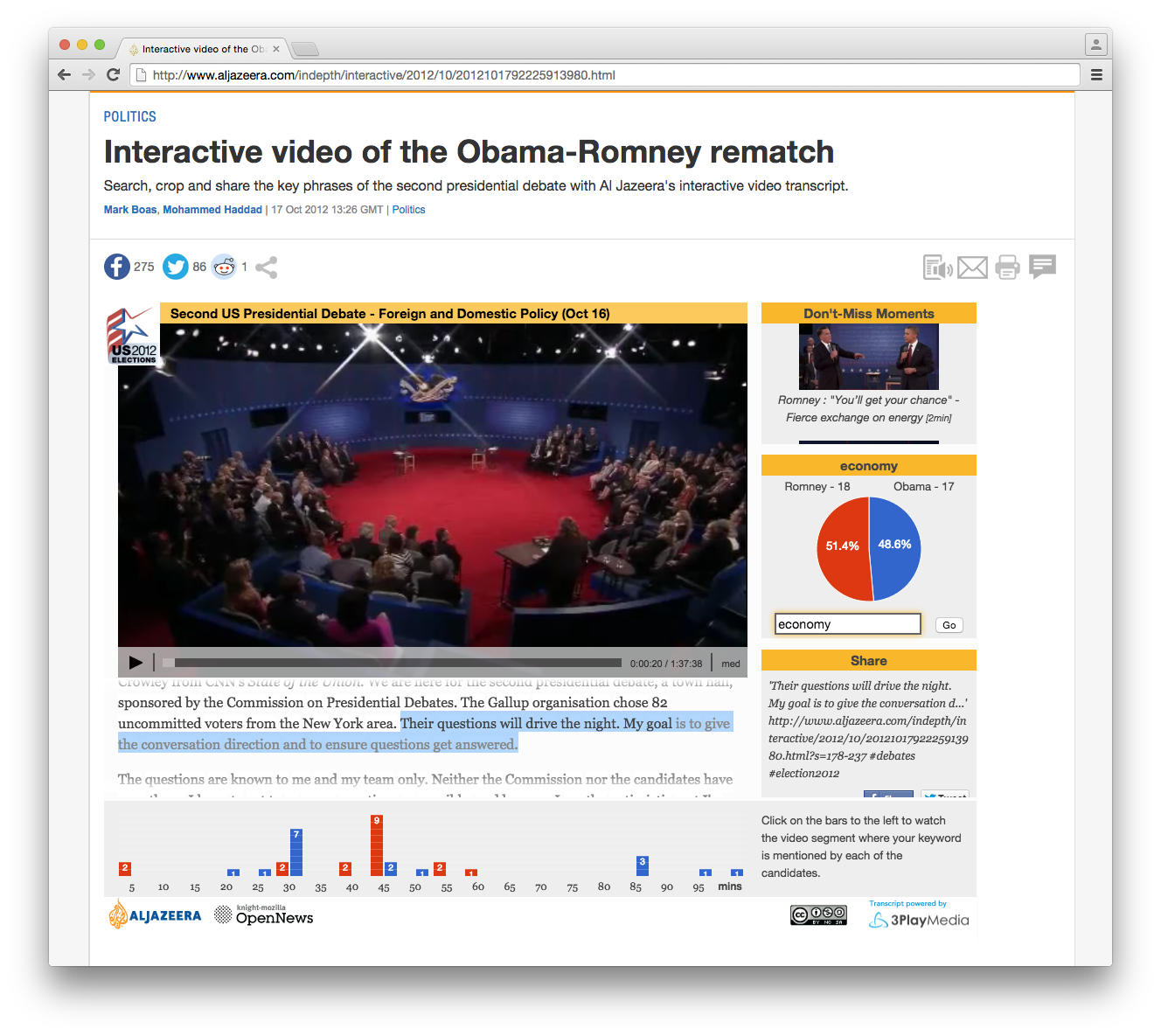
Various interesting uses of video on the web, both in form of tools and editorial projects.
This is a modified version of the second chapter, literature review, of the final project dissertation I did for UCL Msc in CS (2015).
The project consisted of identifying a problem statment, and developing a software application as part of a placement at The Times & Sunday Times in London.
The resulting application was quickQuote, a tool to easily identify and share video quotes, you can read more about it here.
The porpuse of this blog post is to keep an up to date list of projects that are doing interesting things to do with video on the web. I am mostly interested in projects were we go beyond "videos as black boxes" on the web, and get a programmatic access into the video. Often times this is done with the use of time-coded transcriptions.
Background
Newsroom challenges
To best understand the challenges in developing software in a news environment, I referred to the leaked New York Times Innovation report.
The biggest issue highlighted in the report was that flagship projects such as snow falls
were time consuming and a lot of effort went into the making of a one of piece with a relatively short life span.
We are focused on building tools to create snow fall every day, and getting them as close to reporters as possible. I'd rather have a snow-fall builder then a snowfall.
- Kevin Delaney, editor of Quartz p36 NY Times Innovation report
The NY Times competitors such as BuzzFeed, were instead able to separate form from content. The best example is a dialect quiz by the NY Times, that was widely popular, and BuzzFeed, inspired by the format made a "Quizz builder"
and after the first release, published 20 variations with minimal effort.
This consideration of building a system rather then a one of editorial piece is the initial inspiration behind most of the projects I've been working on, which you can read more about here: autoEdit, Interactive databate #buildTheNews, OneStory at BBC #newsHack, quickQuote - Times & Sunday Times.
At the end of this post, I'll give a summary of each one of these in relation to the other projects described below.
V.A.R.K.
The other consideration that guides most of the projects I work on comes from VARK, idea of the variety of learning styles.
Simply put, different people learn in different ways. Five main learning styles are identified, visual, auditory, reading and writing, kinaesthetic and multi-modal. The core concept is that each individual as one (or more) preferred learning style. But also, more crucially, that the same information can be delivered in different ways to meet the different learning styles.
Applying this consideration to the publishing of news article, forces us to re-consider the publishing of text based articles and the use of multimedia to engage a wider audience taking into account the variety of learning styles.
As a practical example, in the making of quickQuote this consideration guided a lot of the assumptions to test through the investigation of the problem. And in fact in the final web application the process of adding the corresponding video segment to a text quote, is taking into account the variety of learning styles. As the viewer is being delivered information both through auditory and reading and writing.
I am now going to consider similar solutions and different approaches to working with video transcriptions on the web.
These are going to be divided into tools, and editorial.
Tools are those projects that allow the user to make something, such as provided a video and returning transcriptions. While editorial are those projects that are more about the content and the delivery of information. I will start with the editorial project as we will see, in this context they often are a starting point for developing tools.
Editorial Projects
Aljazeera Debate Obama - Romney
In the Aljazeera Obama - Romney debate the word accurate hypertranscript was done manually.
What I like about this project is that it gives a way into the video, allowing to search the text, and provide some basic infographic, through a pie chart, on the search terms, you can see how many time the respective candidates have mentioned a certain word.
You can see the code open source on github
I looked into the code from this open source project by Mark Boas both at The Times Build the news hackaton and at BBC news hackaton.
Some of the constraints in this implementation are due to the technology that was available at the time it was implemented.
It uses JPlayer, it's not responsive, and it uses popcorn js to make the hypertranscript connection with the video.
It's also interesting about this project that the developer put an "Easter egg" that would let the user play only the sentences with a certain word in it, adding the query in the URL ?k=economy&t=1000.
Where "economy" could be any keyword, and t is for the time interval we wish to assign to each sentence.
https://www.aljazeera.com/indepth/interactive/2012/10/2012101792225913980.html?k=economy&t=100
However this was not made available as a function in the actual GUI of the application.
This feature is similar to the video grep project discussed below.
Aljazeera Obama state of the union archive
This project generalises the previous one at an archive level.
But again as far as I am aware no automation was used to deal with the transcriptions or the different video input.
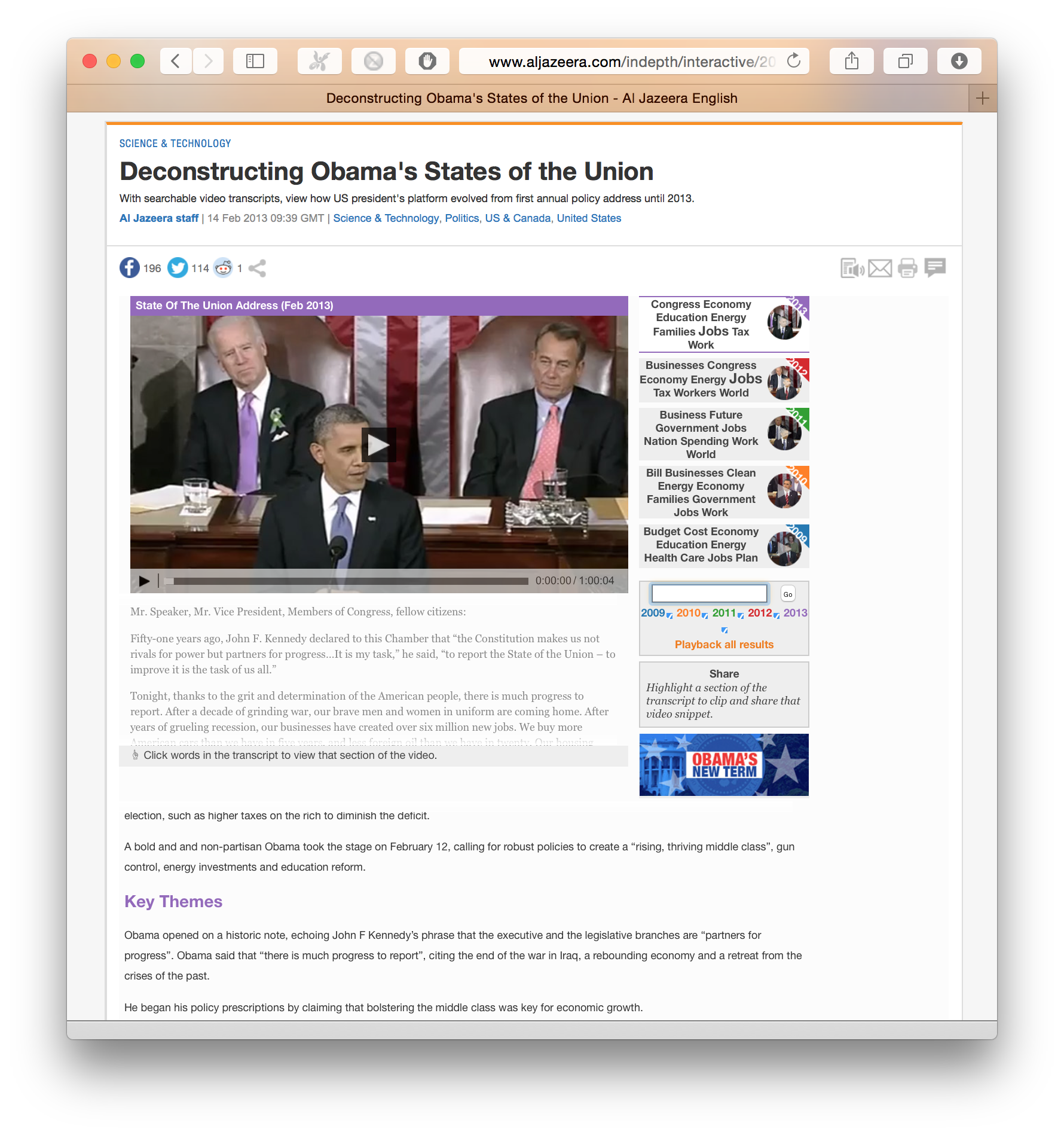
This is where I got the idea for a system that could take a video in perform some kind of analyses.
Also interesting about this project, is that there is a section providing a summary for each video.
Palestinian remix
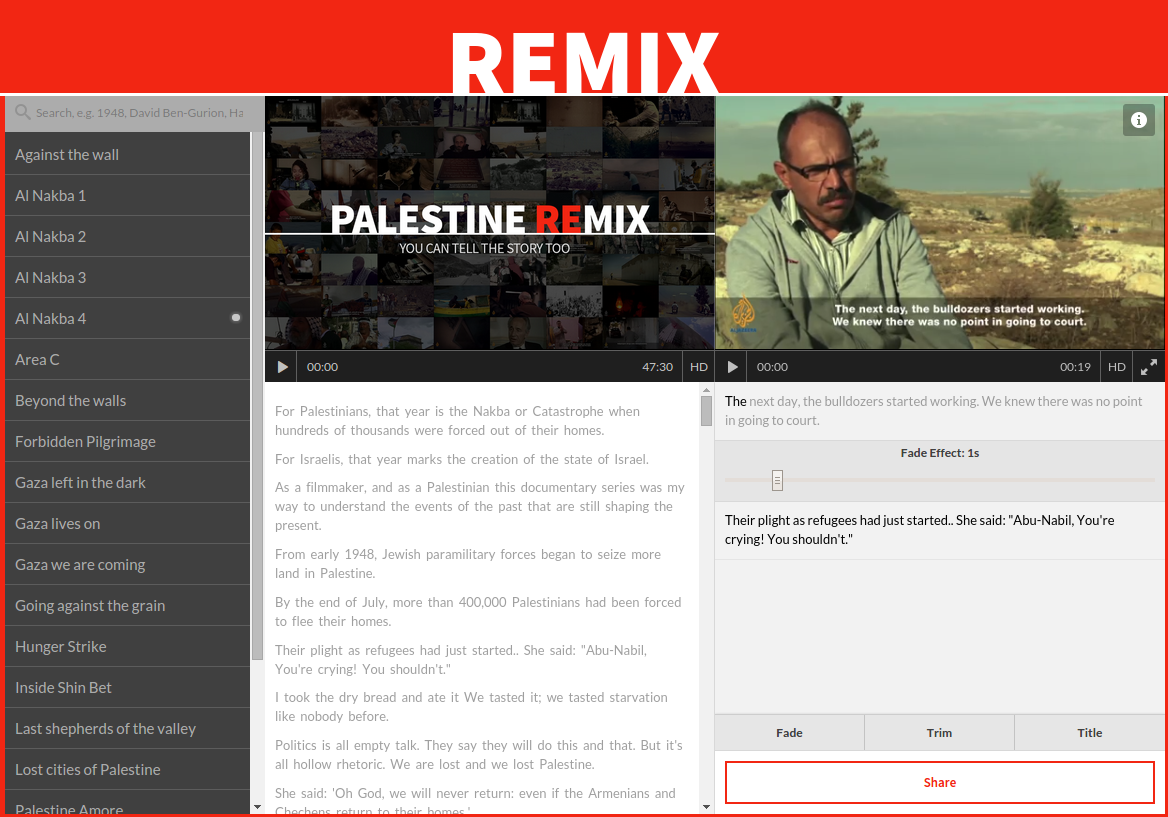
Palestinian remix by Aljazeera is an archive of documentary film about palestine, that allows the viewer/user to create their own text based edit. See demo
However the "final cut" cannot be exported as video file, but can be shared online.
Mandela speech
The Times & Sunday Times newsroom develoepr Ændrew Rininsland made piece about Mandela (paywall).
The Hypertranscript was done using using hyper audio converter (code on gihub) component of hyperaudio,
But the transcription was done manually using VLC and Notepad and subsequently a software to make subtitles, adding the text with in and out points, to then get an srt to convert in hypertranscript maker. Which as you can imagine was a time consuming process.
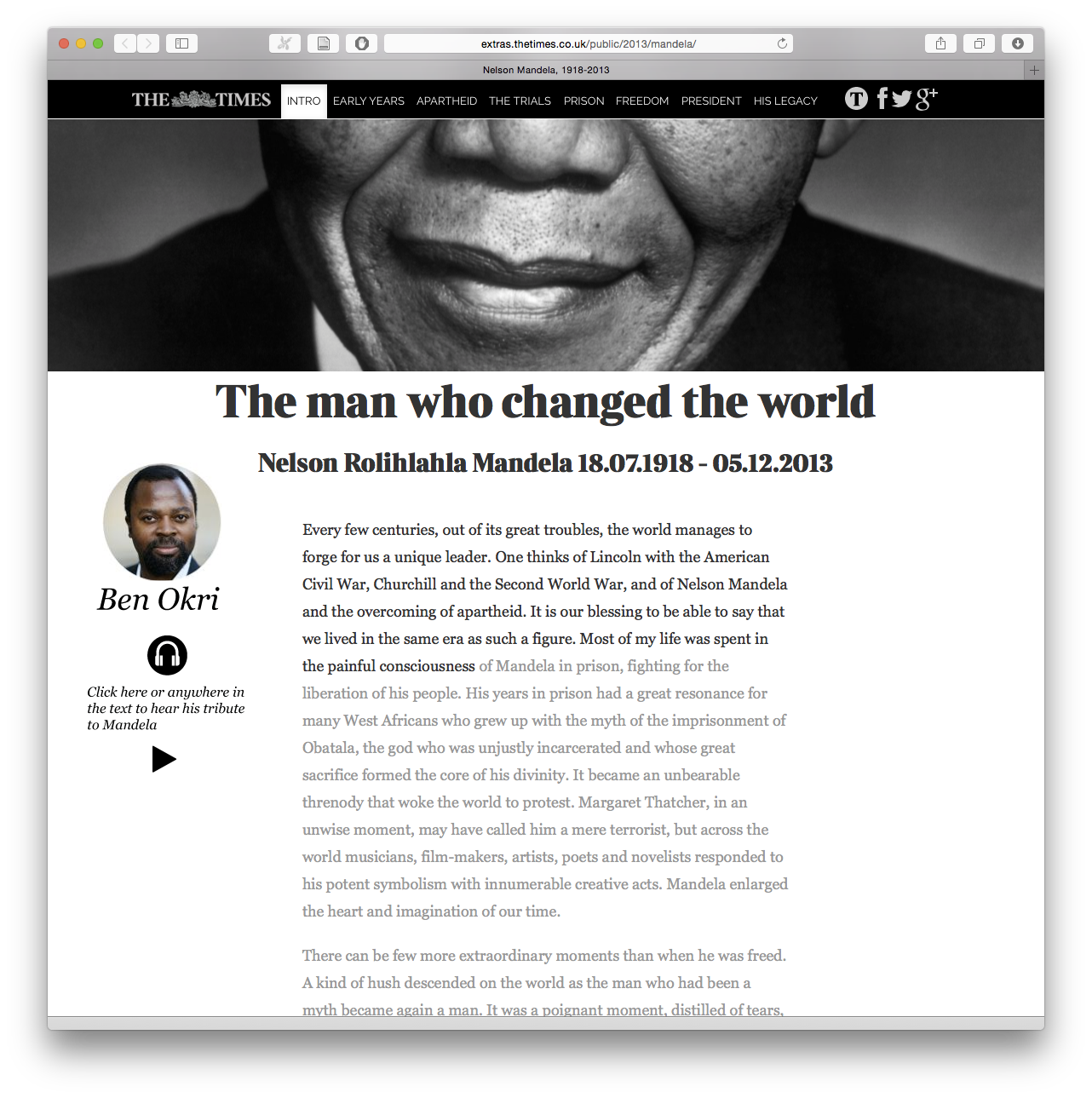
The piece used audio only. what I like about it, is that the text changes color as the audio is playing, as you can see in the screenshot.
Built with a Google docs-based back-end using doctop and getbootstrap.com front-end.
However the project relying on google doc as a backend, through doctop or tabletop are at risk of being effected by google changes in the API.
Perhaps better solution to make the most of the convenience of using google docs as a CMS for the journalist would be to keep google docs in sync with a database that updates the application. this way if the connection between the database and google docs where to drop due to changes in the API the front end of the application would not be effected.
Tools
Video grep (open source)
A project by Sam Lavine (blog), as name suggests video grep (code on github ) it's a command line utility to search audio or video file and return a file with cut segment.
There is also a audio grep version.
It seems to be composed of a Python library that given a video media (code on github lib doc)
you can search and return all the sentences where the word "time" is mentioned from a film or this example where using same tool it extracted all the parts in the speech where Jay Carney, the former Press Secretary says “what I can tell”. this does use our subtitle file associated with the video as a starting point and then Video Using FFMPEG.
videogrep requires the subtitle track and the video file to have the exact same name, up to the extension
However in the project page there is also a link to a OSX mac app version (using electron and node https://saaaam.s3.amazonaws.com/VideoGrep.app.zip) of video grep which provides a GUI to the command line utility, as well as the possibility to add a video and have a transcriptions been automatically generated.
The transcription is generated using pocketsphinx running locally offline on your system.
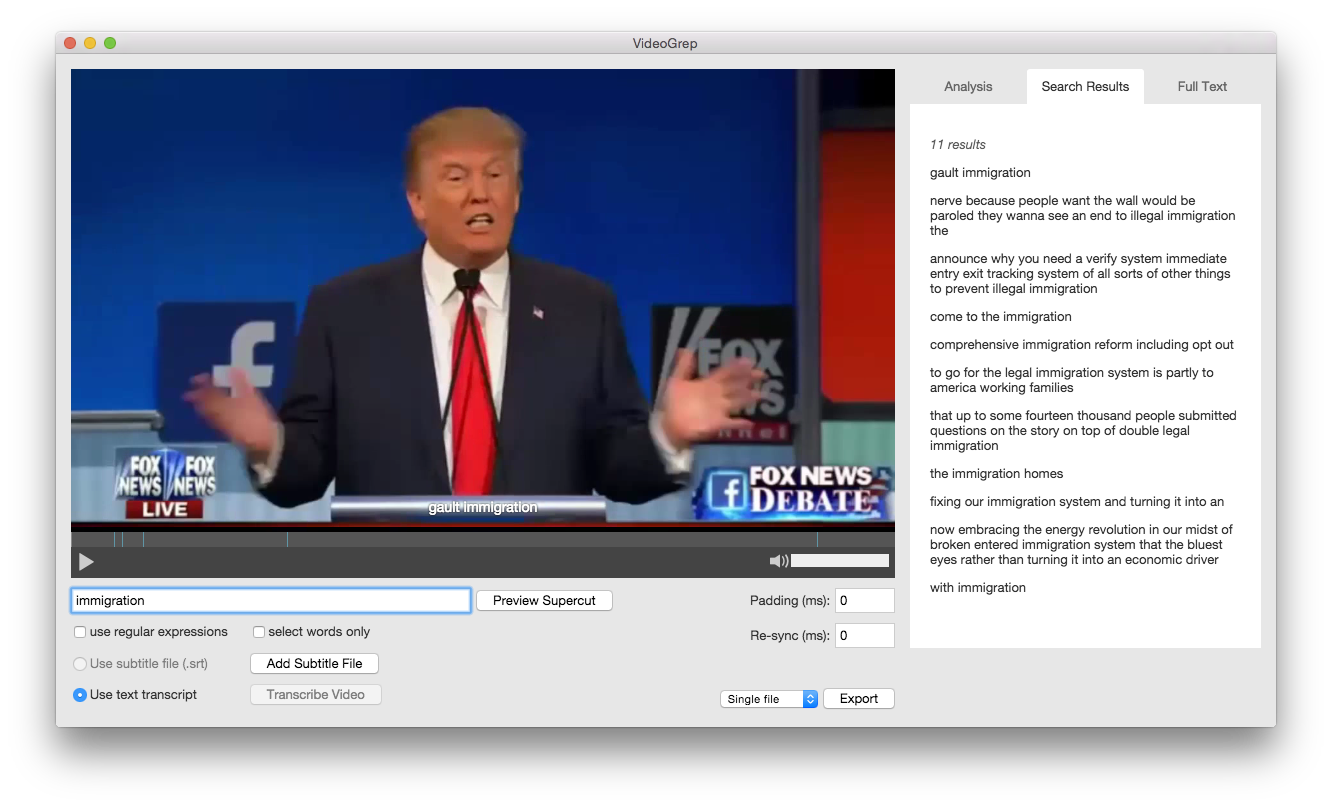
There is however no level of granularity control on selection, or hypertranscript.
This project reminds of the Casseteboy video artist, that does video editing mash ups, generally of politician's speeches.
However Casseteboy in this interview mentions he uses a manual and time consuming workflow to search and identify the relevant video segments for his edit.
Making these videos takes a lot longer than many people might assume, doesn't it...
It is a long time. The original Apprentice video, we were working on it on and off for a couple of months. This new one we've done is well over a month. If you think about just watching the material, say a boardroom scene lasts half an hour, it will actually take an hour, an hour and half to get through it the first time around. You just keep stopping it, taking samples of bits that might be useful, filing them and then categorising them. So you can only do a few episodes per day.
BBC Snipets (internal to BBC)
It allows BBC employees to search for programs in the BBC Archive(going back only to the last 5 years), searching across the text of the subtitles. It uses a form of hyper-transcript to keep audio and video in sync, and allows to cut video segment from BBC archive.
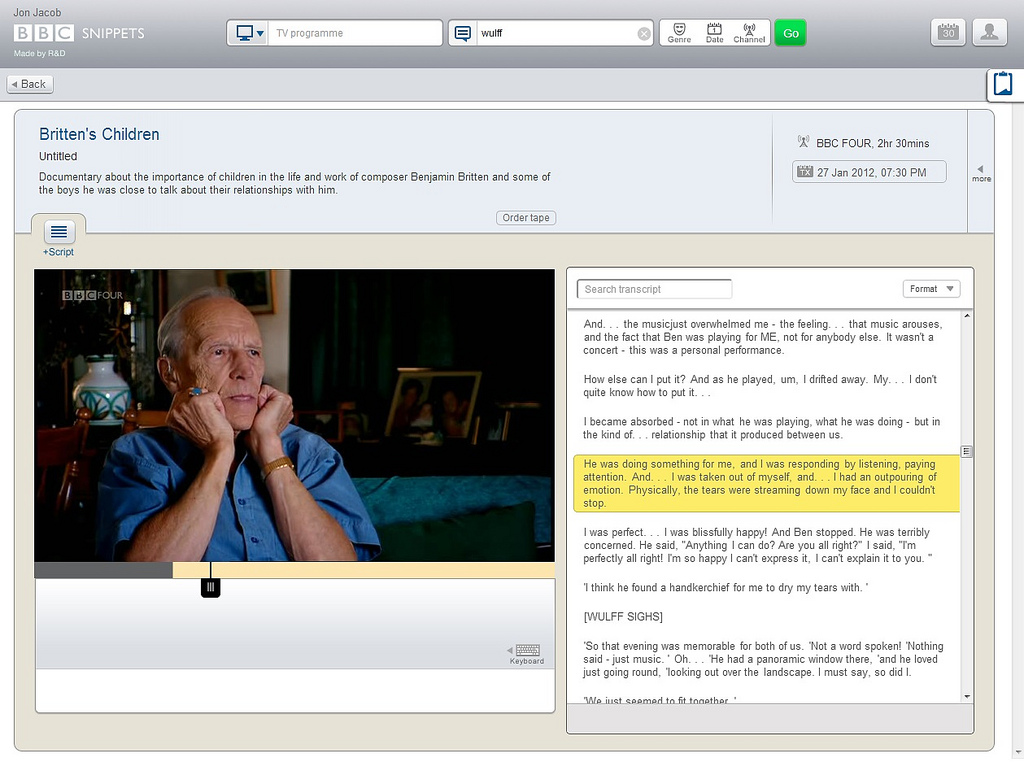
The hypertranscript is sentence accurate rather then word accurate.
Constrained to BBC archive, and because uses already made subtitles, no real system to deal with un-subtitled vide os and transcriptions generation.
No form of analyses on transcription, auto tagging, summarization provided.
most importantly the cutting of the video segment is done at the level of the video time-line. and not of the text.
Moments - prototype (open source)
Moments is a web application proof of concept that allows a user to add an inline drop-down video snippet to a text article. It uses a CMS for the journalist and has a published view for the viewer. It does not use transcriptions.
From this project I initially got the idea for an inline text dropdown of a video element for quickQuote.
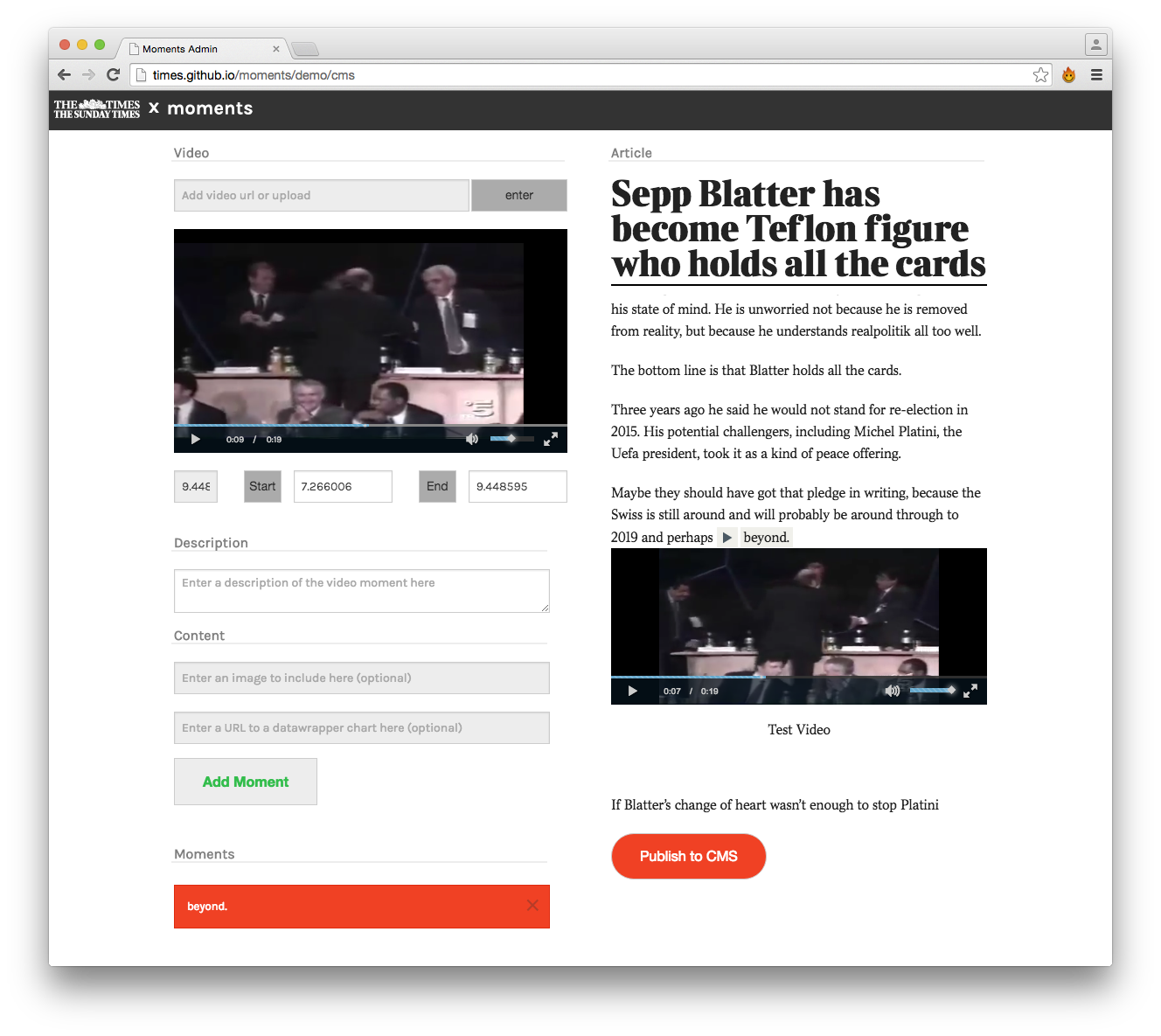
It was prototyped by the (London) Times Digital Team and is the winner of the 2014 Editors Lab at GENSummit2014. However as mentioned this is a proof of concept and not a fully working application.
hyperaudio (open source)
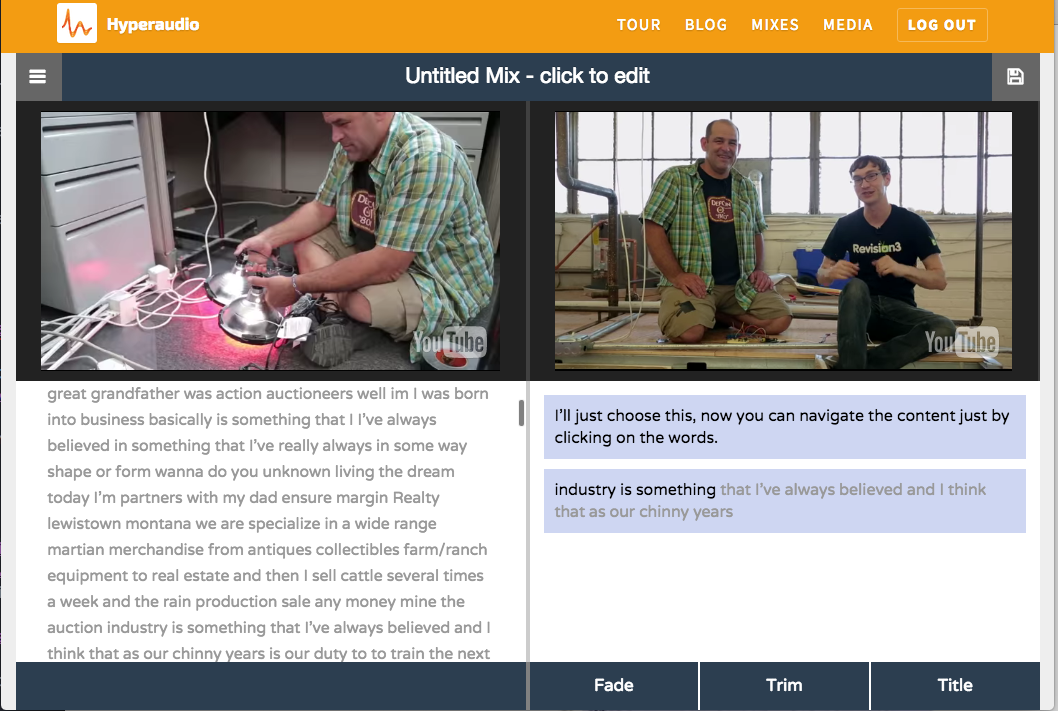
Hyperaudio is an open source project that generalises the idea of the palestinian remix, to any youtube video.
It uses hypertranscript to make remixes of videos based on their transcriptions/subtitles.
Similarly you cannot upload a new video, unless is available on youtube or the internet archive, and you cannot export a edited video file.
You can however upload a srt file to convert it into an hypertranscript.
and you can transcribe a video to create an hypertrnascript using their system.
prEdit(payed)
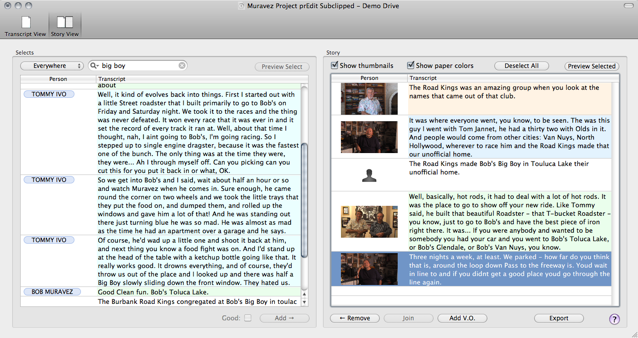
preDit similar solution to hypertranscript but is desktop based for OSX only.
It provides integration with editing software, and preview of the text assembly.
Interface is not very intuitive, setup is very fiddley, and requires already having transcriptions as a starting point.
The presence of tagging, and categorization system is an interesting feature but poorly implemented.
Interesting article on the idea behind it.
Transcriptions Tools
oTranscribe (open source)
Made by newsroom developer at WSJ Elliot Bentley it's very popular with journalists.
It facilitates manual transcriptions of video and audio, with intuitive interface and a few keyboards short-cuts.
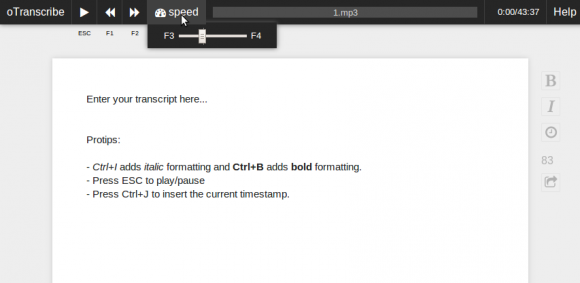
No automation of the transcription process thou.
supports adding time stamps similarly to F5, and it lets the user export as markdown, plain text or json. As well as t
Hypertrasncript converter(open source)
The developers from hyperaudio have automated the process of parsing srt files into an hypertranscript with an hypertranscript converter written in JavaScript, this library was developed to support hyperaudio pad project .
It's all client facing javascript
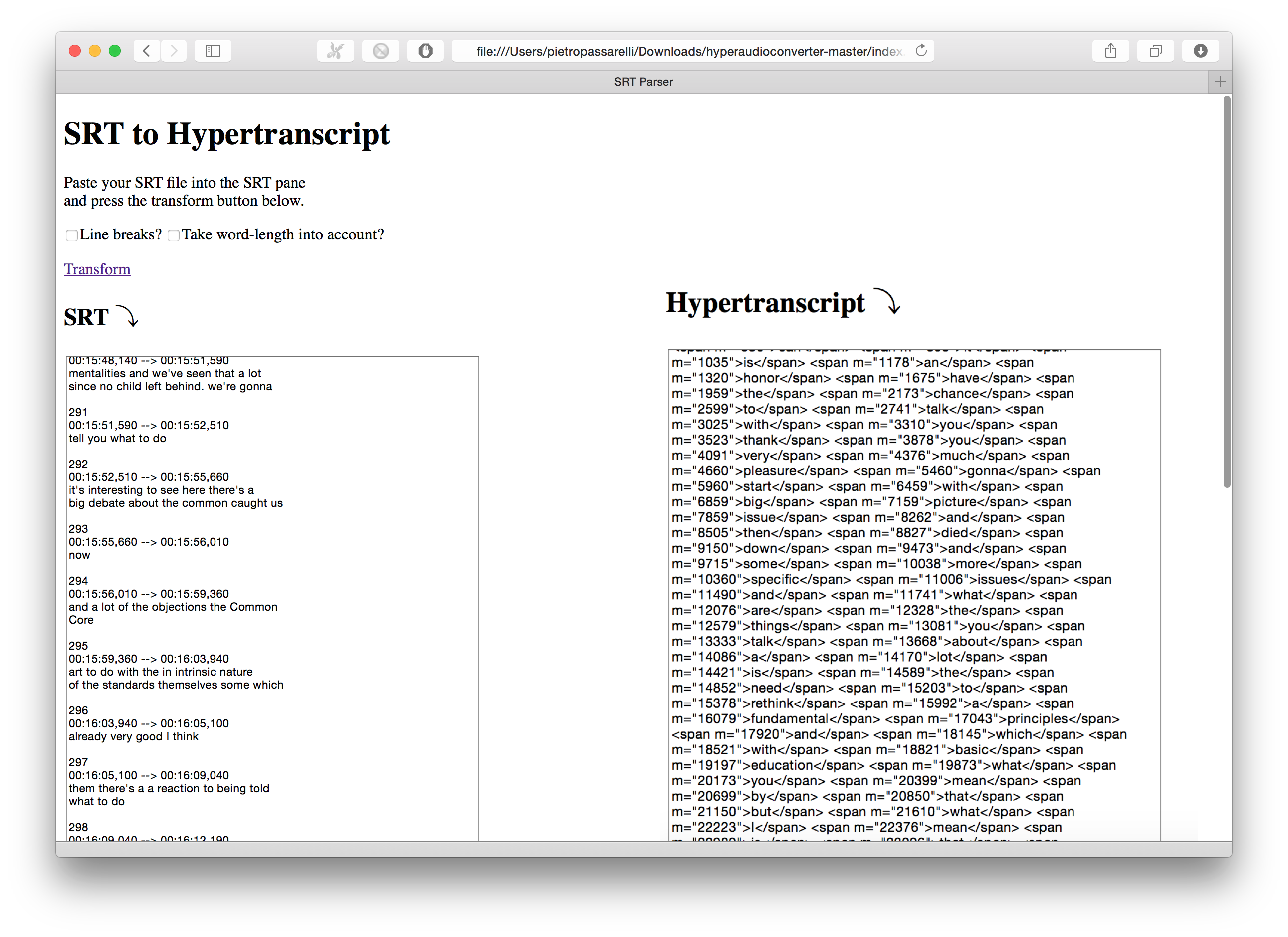
From the line accurate time code of the srt file it works out a word accurate hypertranscript, with each word in a span tag with a relative time attribute.
The parses was initially from the popcorn library popcorn.parserSRT.js
Pocketsphinx (open source)
Based on CMU sphinx pocketsphinx can be used to make your own speech to text recognition system.
A great example of this implementation can be found inside video grep Mac OS X electron app https://saaaam.s3.amazonaws.com/VideoGrep.app.zip.
F5 Transcription (payed+free trial)
F5 is a desktop transcription tool, made by German academics. It allows the user to transcribe a video manually, with a convenient interface the application provides timecode stamps on new line input.
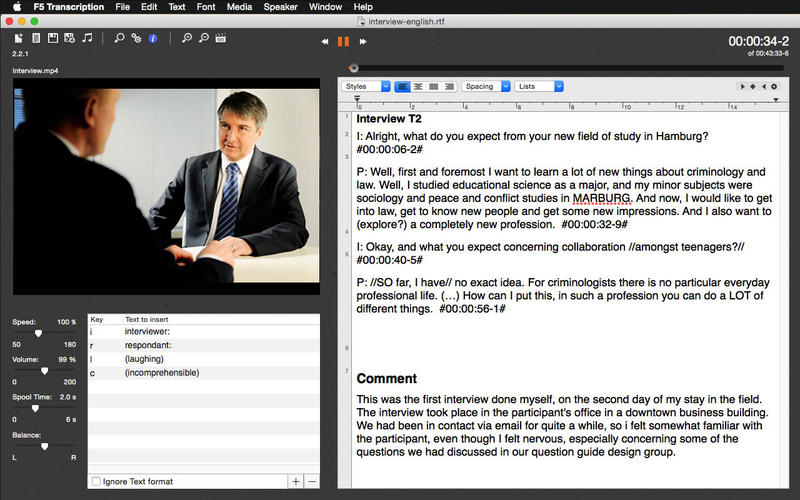
F4 Analyses (payed+free trial)
In subsequent versions of F5 they released F4 analyse, which allows to takes those same transcriptions and add human tagging to it for qualitative analyses.
Very interesting is the idea of providing insight into text of transcription coding it's content with tags, and adding summary, this however is done manually by the user, while using NLP APIs this part could be automated.
YouTube captioning (free)
YouTube has a captioning service and clickable transcriptions.
However their transcription is mostly aimed at subtitles and even in the transcription view, it's not word accurate, it's line accurate, perhaps because it uses the subtitle file generated during the captioning to model the hyper-transcript.
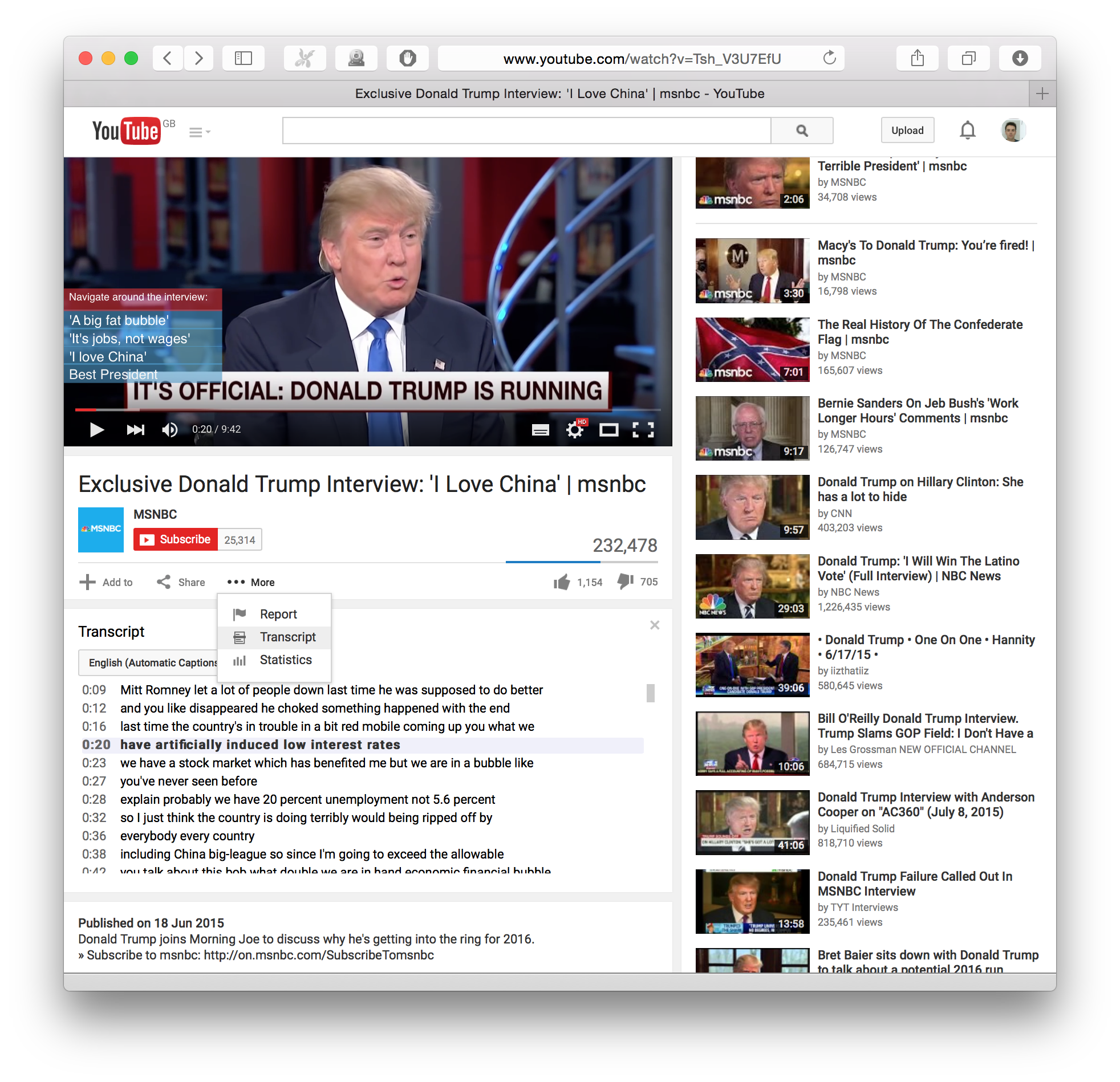
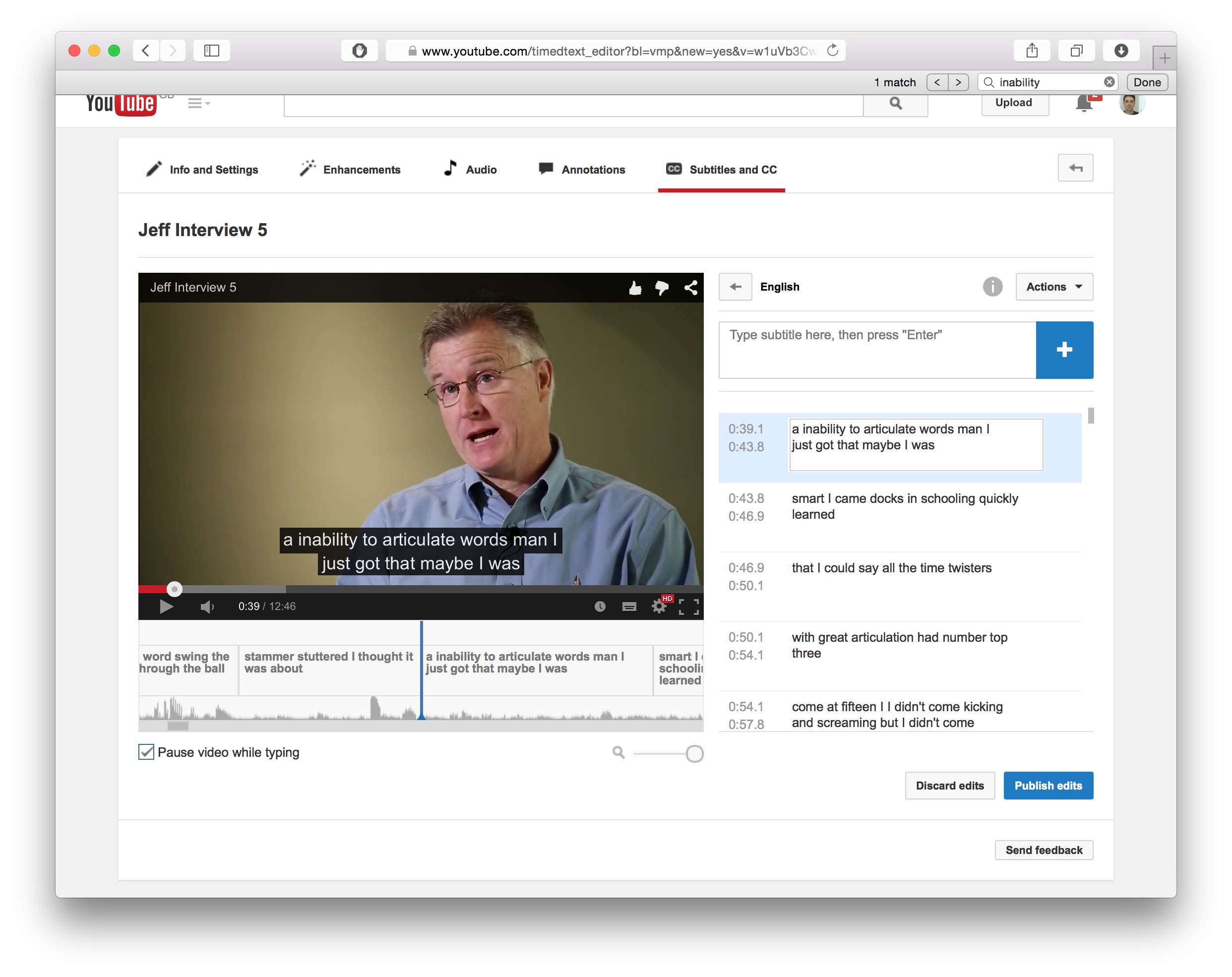
The advantage of YouTube automated captioning is that it is constantly improving and becoming more and more accurate. And supports a variery of languages. The screenshots above might in fact be out of date already and is worth looking it up for yourself to see if anything interesting as changed from the time of writing.
YouTube also provides a data APIto retrieve captions.
however it was not clear how you would go about retrieve automatically generated captions through the API, as these need for the language to be set before the caption is generated.
But most importantly the disadvantage is that, in version two google announced it was going to discontinue access to the captioning service through the API.
However despite this still being available through version 3 of the API.
Google/YouTube might have no commitment on their part in maintaining this service as part of the API long term, as they have recently launched launched Cloud Speech API.
Automatically generated transcriptions are a big component of these type of project. Therefore is sensible to define an interface for the speech to text API component in order to be able to change speech to text provider in the future should the service being discontinued, or found a better solution.
Spoken data (payed+free trial)
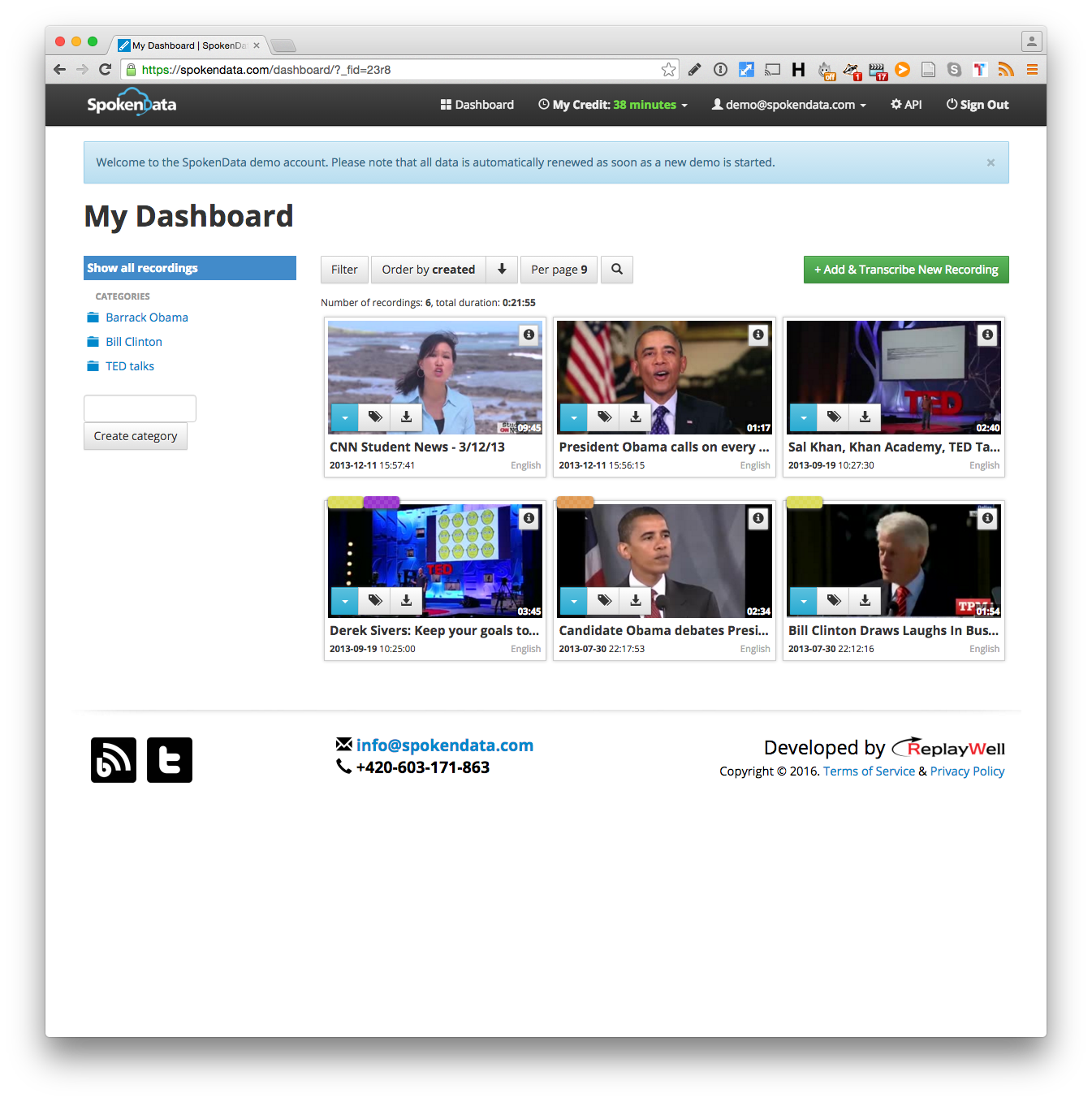
Spoken data is mostly tailored at small teams of professional transcribers, but also individuals requiring transcriptions.
With it being a smaller company they were more responsive in making changes.
For instance I needed to be able to delete a video uploaded to their system through the API,(to avoid issues of duplicates in their dashboard if the user uploads, deleted and uploads again the same video in quickQuote) and they were very quick at implementing that feature.
They also provided other functionalities such as a view to edit the transcription, with a defined URL that can be accessed with the uid of the video. This could be useful to give the users of my app a way to edit automated transcriptions without having to implement it from scratch.
https://spokendata.com/transcription/5937
For more on their API see here, which also provides speaker diarization.
Spoken data also offer the option to pay a human through their system to go over the transcriptions and make them 100% accurate. Which is a great option if you want to outsource your transcriptions completly but retain some control over the process.
Checkout the demo account.
Trint (payed+free trial)
If you are looking for a semi automated workflow when working with transcription, where a first draft is generated for you automatically and you can then review and polish it up, Trint has probably the best, easiest user experience.
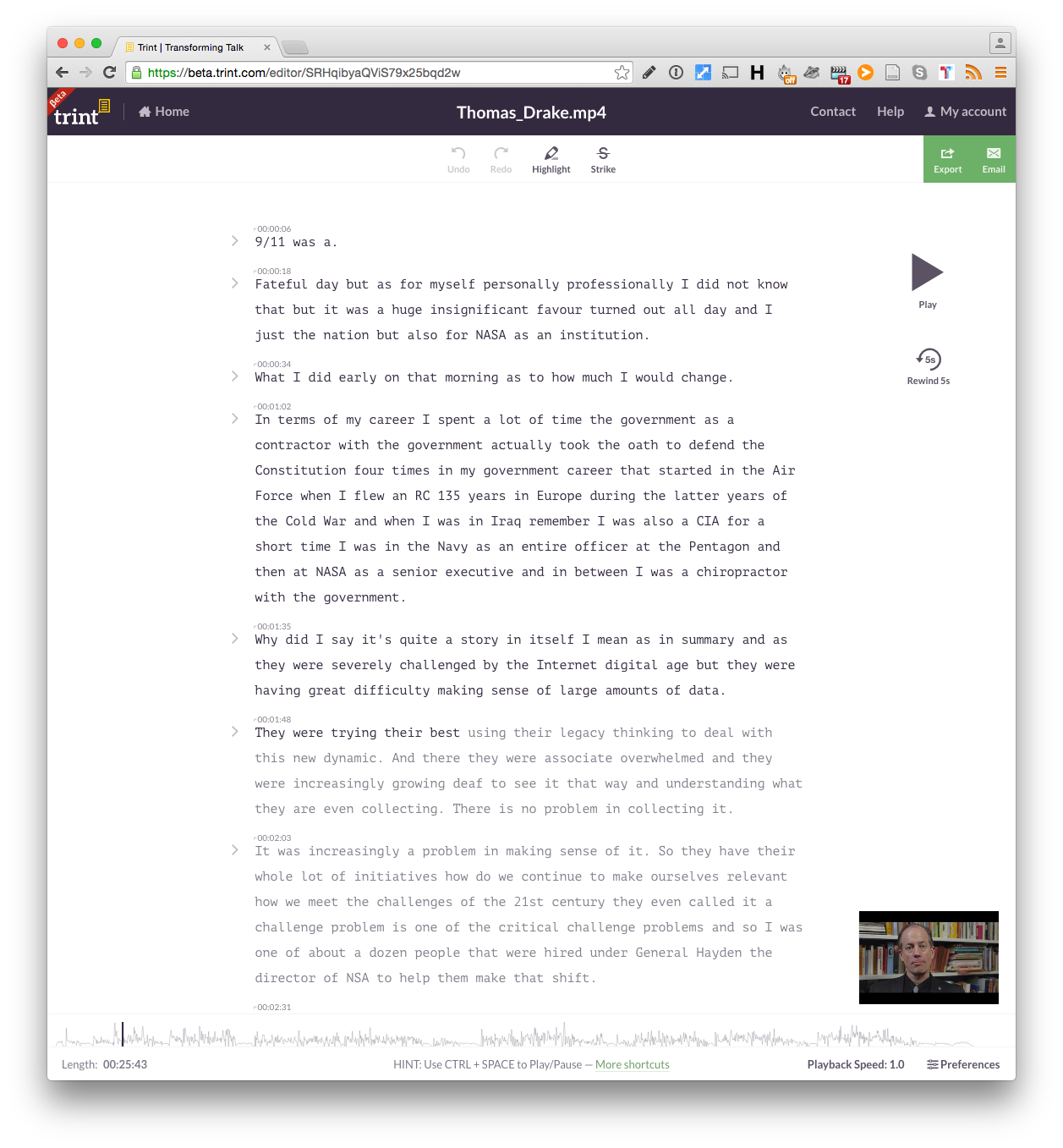
However Trint is not open source and it is a commercial project. But they do give you some free time to begin with if you want to check it out.
Interesting is the possibility, borrowed from the autoEdit export to EDL component, to export selections as EDL.
IBM Watson Developer Cloud(payed+free trial)
IBM Watson Developer Cloud, speech to text
Check out the Speech to Text demo and choose from pre-recorded audio, upload a WAV file, or record on the fly in US English, UK English, Japanese, Spanish, Brazilian Portuguese, Modern Standard Arabic, or Mandarin and watch the service in action. The API returns metadata providing timestamps, confidence, and alternative hypothesis. The demo also includes options to help Watson learn and improve.
It seems to also work with a live audio stream, which would make it great for live video/audio applications.
First thousand minutes per month are FREE. Additional minutes are $0.02 per minute.
It provides word accurate time stamps.
In chrome and firefox you can also use the computer's microphone through the browser, if you are working on a use case that might need that, eg user narration on a video.
It also identifies keywords, and makes a note of the timecode they accour at.
My Projects
With a background in documentary production, I have a long standing interest for story crafting, and working with transcriptions effectivly, so here are some of my projects that came out of this exploration.
autoEdit
autoEdit, fast text based editing of video interviews. Is a "Digital paper editing” software.
To make a script from a selection of lines from the transcriptions of interviews.
You can then export as an EDL. This can be opened with the editing software of your choice to reconnect the corresponding video into a sequence, and finish working on your rough-cut assembly.
I am currently working on this, and have various prototypes, with different stack at different stages of development as I am trying out different approaches.
Initial prototype
The initial prototype for autoEdit, consisted of two scripts. one to parse sbv subtitles files made with youtube into a csv file. to upload to google spreadsheet. And the other to convert the csv file into an EDL.
I used that in an actual production I was working on, and while I saw that i worked and saved me a ton of time, I knew it was worth spending some refining this.
rails MVP working version
The rails version in beta is available in beta at autoedit.io code on github and more detailed explanation here
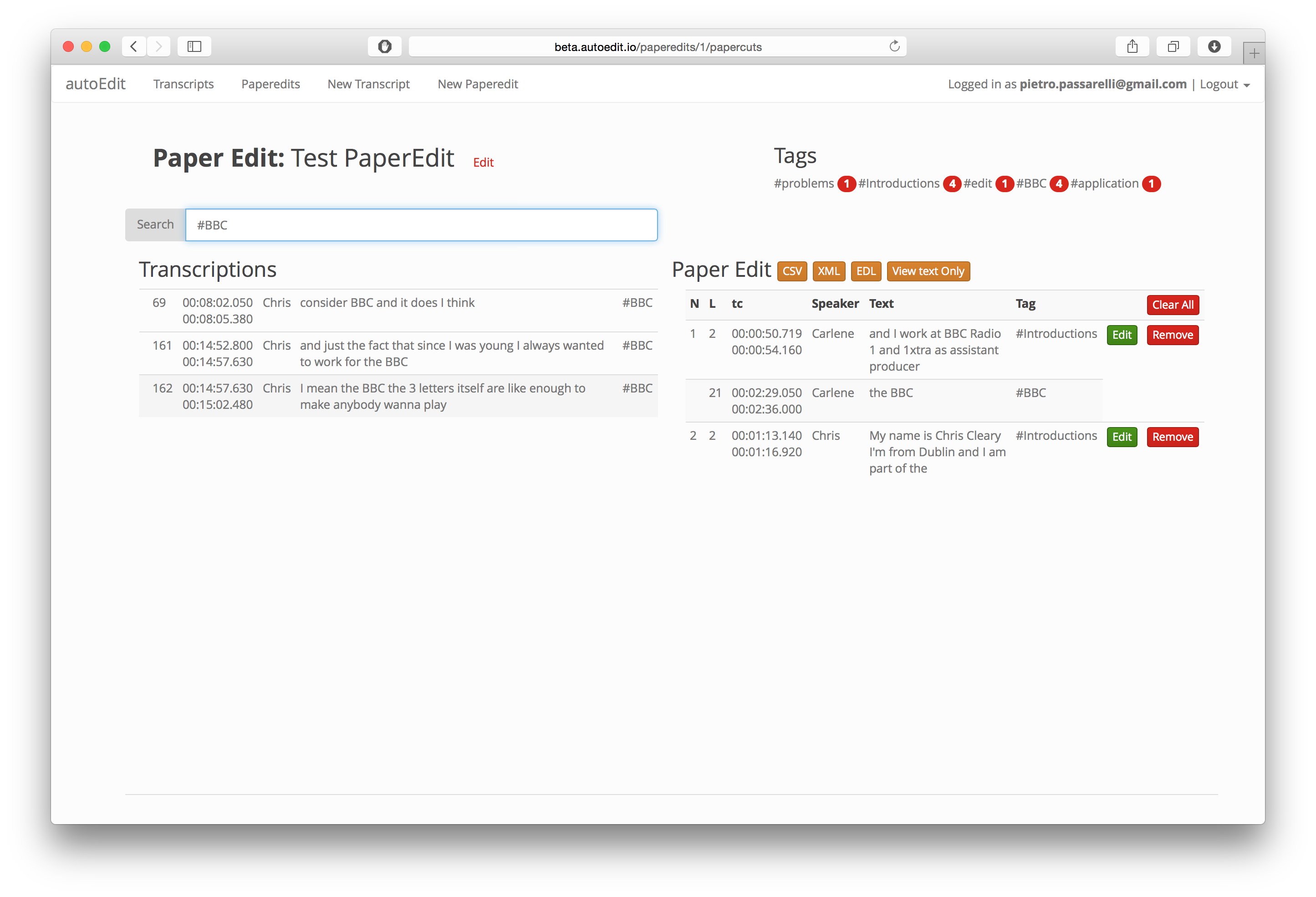
In this version the transcript is modeled after the srt file, and therefore the granularity is at line level and not work level.
The user uplaods an srt file, makes a text based assembly and export an EDL file, that can be used to continue the editing in the video editing software of choice(Premiere, Avid, FCP7).
nodejs + NWJ prototype
I am currently trying a new approach using node and nwjs to make it as a web app that can run on desktop offline, to see if this could give more flexibility to the implementation, and when working with broadcast quality footage.
The code is on github however as I am still working on it, it's in need of refactoring and documentation. But if you are interested do drop me an e-mail.
Build the news "debate analyser" proof of concept
This was a proof of concept for a system that given a video would generate transcription, identify the different speakers, provide summary of main topics and keywords as well as emotional charge of the speaker. Using the UK elections debate as a use case. Was winner of the Times “Build The News Hackaton”

More details here.
The proof of concept was more of a R&D research, into the feasibility of the various component, with an interactive demo.
To see if we could find points of contacts to bring togethere from various APIs
- automated transcriptions
- speaker diarization
- summarization
- keywords extraction
- sentiment analyses
The code from the Obama-Romney Aljazeera debate was used as a starting point.
This is concept could either be applied to the annotation view of autoEdit, or for projects where working with an audio or video Archive we want to get some programmatic insight into the content of the material.
oneStory
oneStory came ouf of the idea of the variety of learning style V.A.R.K. as mentioned at the top of the article.
The underlying assumption is that you could create a story editor CMS, where with defined equivalence points, the viewer could switch "medium".
For instance you start reading your story as an article, switch to as a podcast while you get on the bus as you are standing, switch again to it as video while you step into the tube, and finally switch to it as multimedia piece once you reach the office. Through the "app" knows where you at with the story when you make the shift.
For more on this here
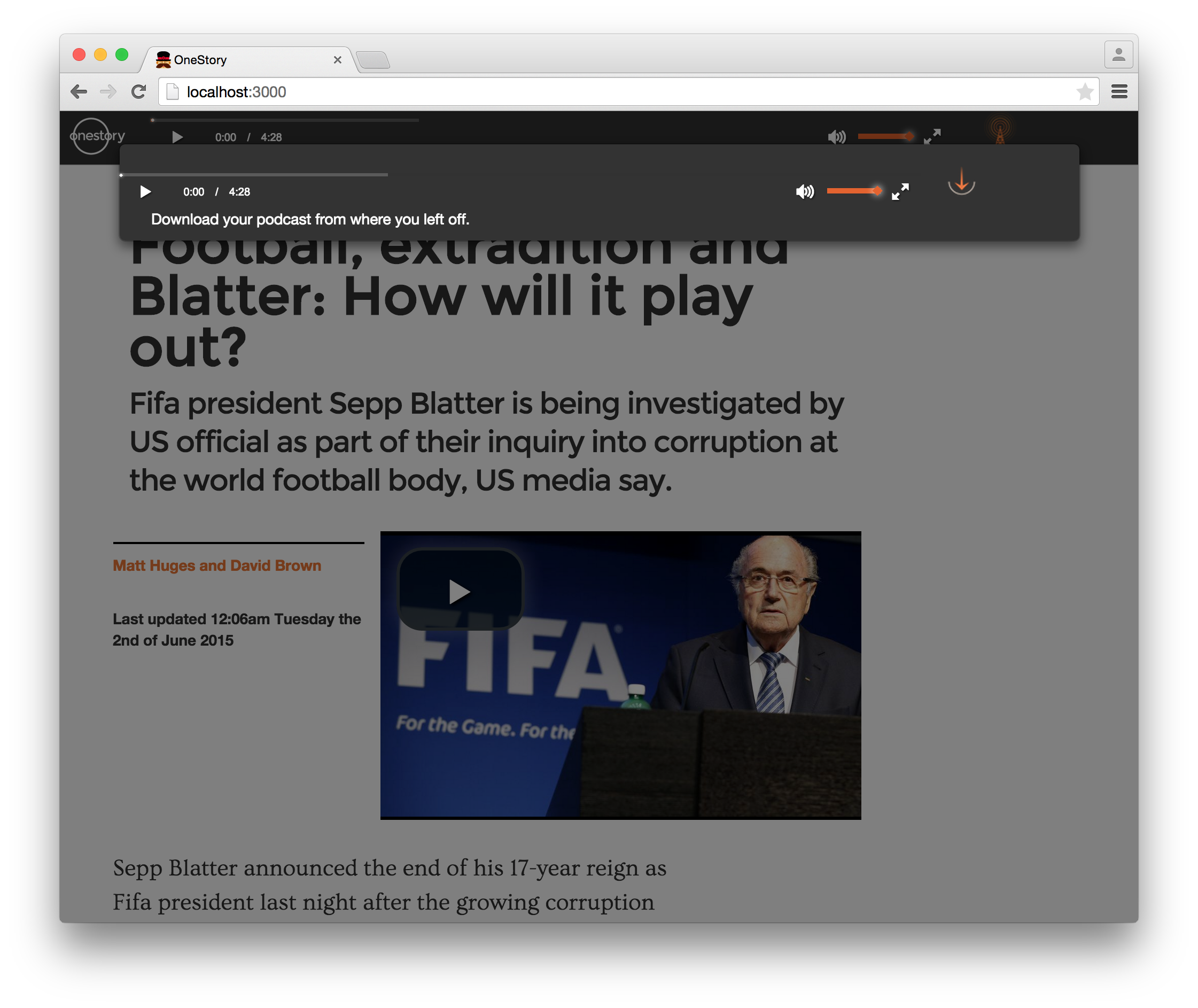
at the Hackaton only the switch from article to podcast was demonstrated.
quickQuote
quickQuote given a video, it sends it to spoken data speech to text API to get a transcription.
When the transcription is done it generates a hypertranscript, that can be used to select a quote.
Exporting a text quote, trims the corresponding video.
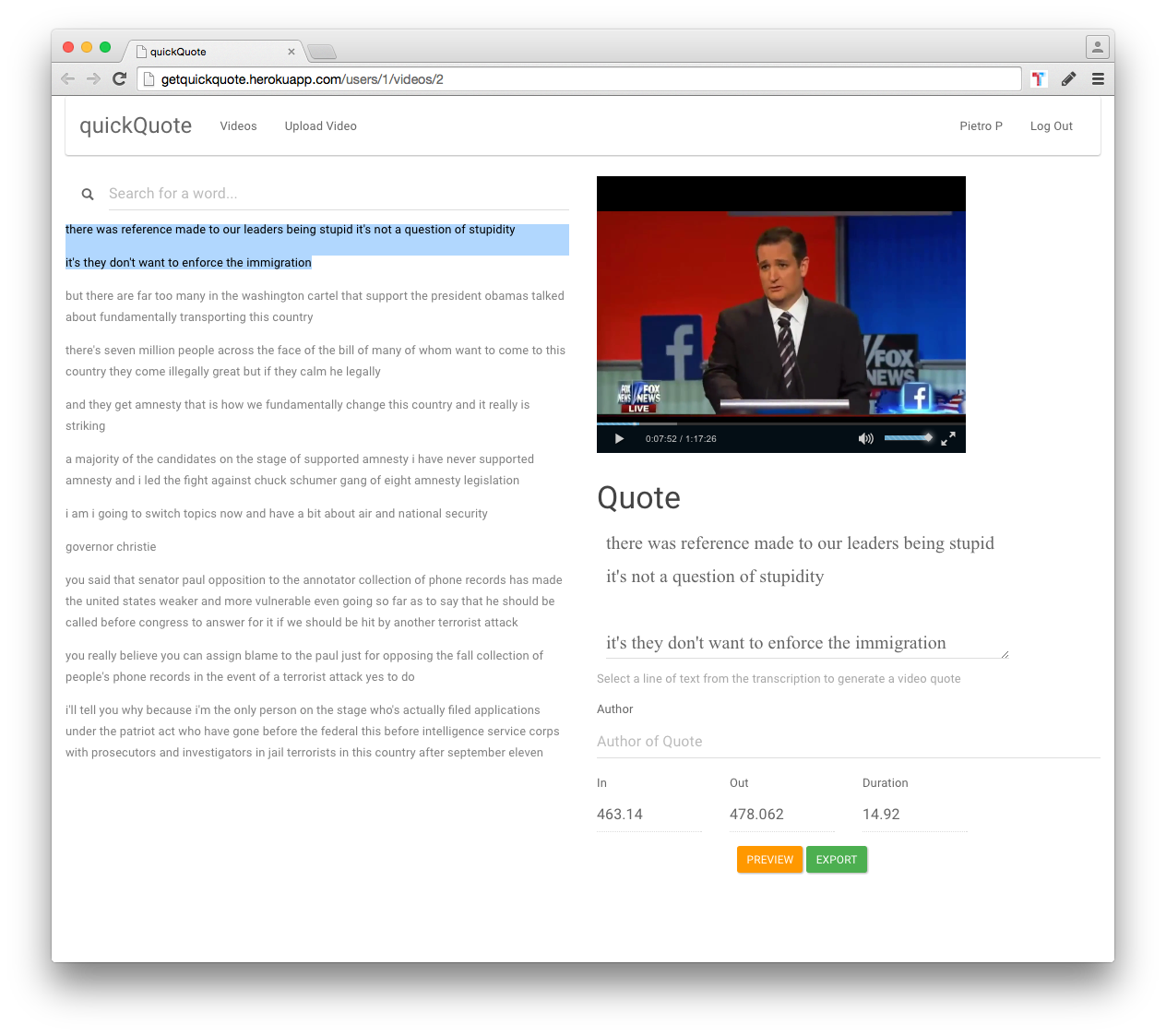
This can be exported either as an interactive video quote or to the twitter video API.
I've since refactored the project from the original rails implementation to Node, (code on github) and added support to export/publish the video snippet to twitter, through the twitter video API.